
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 모듈 패키지 라이브러리
- 컴파일타임
- 런타임
- 마크다운
- 파이썬 문법
- 아이펠 회고
- 윈도우 커맨드창
- 파이썬 주석 변수
- 아이펠
- 파이썬 여러줄 주석
- AIFFEL일기
- 아이펠 일기
- 파이썬
- Python
- AIFFEL 회고
- python 문법
- 파이썬 진수변환
- Aiffel
- Linux
- 마크다운 inline 수식
- PYTHON 주석 변수
- 파이썬 형변환
- 마크다운 인라인 수식
- 아이펠일기
- compile time
- 파이썬 긴 문자열 변수
- Markdown
- 리눅스
- AIFFEL 일기
- 파이썬 여러줄 문자열 변수
- Today
- Total
튜토리얼에도 고난과 역경이 있다.
데이터 전처리의 다양한 기법 본문
인공지능에는 다양한 데이터 처리의 다양한 기법이 있습니다.
오늘은 다양한 데이터 전처리의 기법에 대해 알아보았고, 각각의 내용을 정리해 보았습니다. 그리고 그에 대한 내용을 링크에 남겼습니다.
데이터 전처리 기법
결측치
결측치란, 입력이 누락된 값입니다. 보통 제거하거나 대체하여 처리를 합니다.
중복된 데이터
말 그대로, 중복된 데이터입니다. 혹시 데이터의 특성상 같은 행에서 모든 데이터가 유일해야 한다면, 중복된 데이터를 제거하여 처리합니다.
이상치 outlier
대부분의 값의 범위에서 벗어나 극단적으로 크거나 작은 값. 이상치를 처리하는 방법은 z-score, modified z-score method, iqr method가 있다.
정규화 Normalization
[데이터 전처리 ) 정규화 처리 방법]:
원-핫-인코딩 One-Hot-Encoding
구간화 Binning
그 밖의 기법
로그변환
2019년 kaggle에서 진행한 캐글 코리아와 함께하는 2nd ML대회 - House Price Prediction에서 train데이터의 분포를 살펴보면 다음과 같습니다.
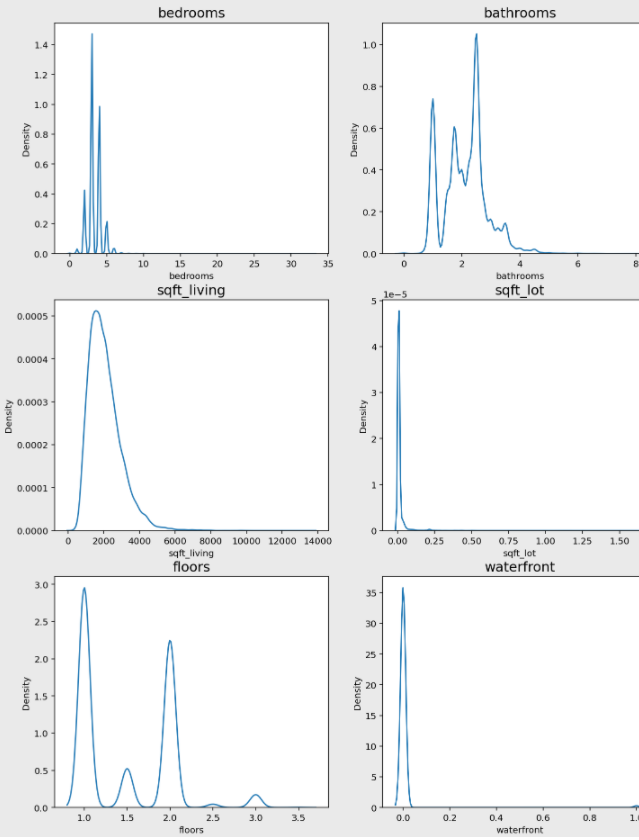
...생략
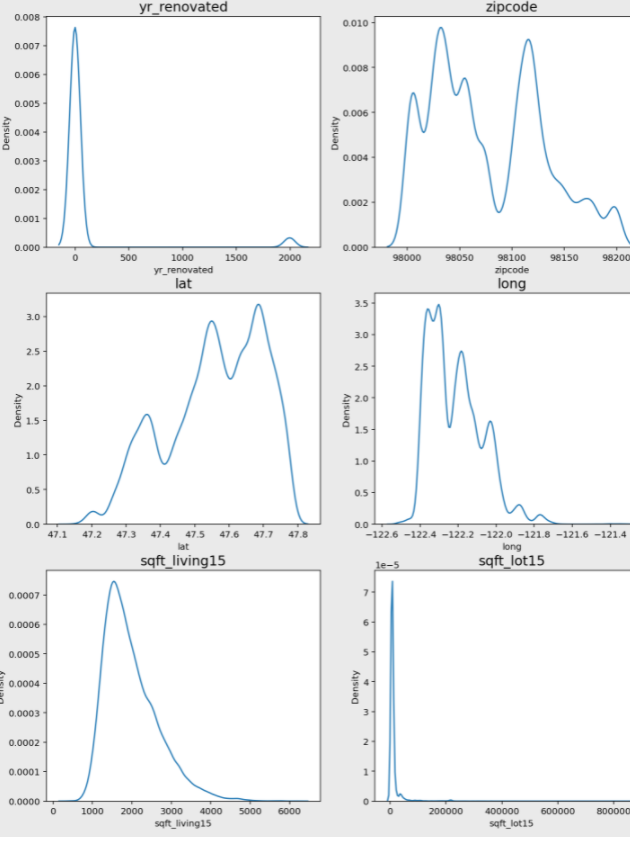
위 그래프 중에서 bedrooms, sqft_living, sqft_lot, sqft_above, sqft_basement, sqft_living15, sqft_lot15 변수가 한쪽으로 치우친 경향을 보입니다.
이렇게 한쪽으로 치우친 분포의 경우, 로그 변환(log_scaling)을 통해 데이터 분포를 정규분포에 가깝게 만들어 주면 좋습니다.
skew_columns = ['bedrooms', 'sqft_living', 'sqft_lot', 'sqft_above', 'sqft_basement', 'sqft_lot15', 'sqft_living15']
for c in skew_columns:
data[c] = np.log1p(data[c].values)위 코드는 로그 변환을 한 코드입니다. numpy.log1p() 함수는 입력 배열의 각 요소에 자연로그 log(1 + x)처리해 주는 함수입니다.
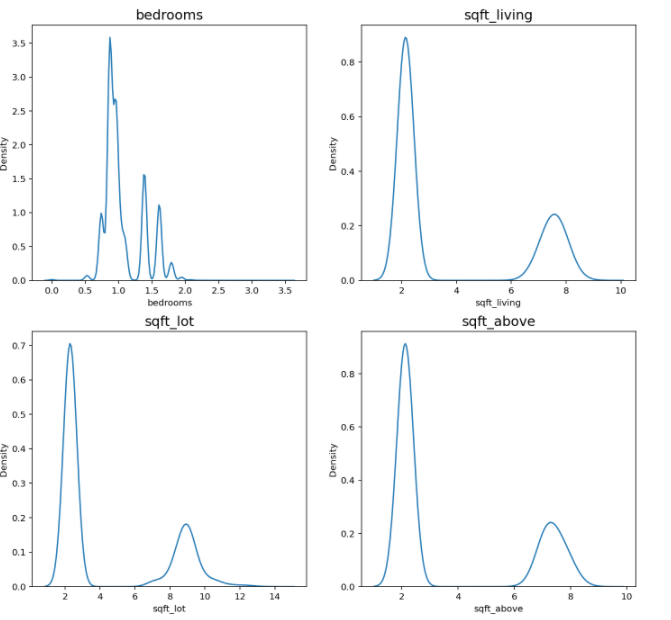
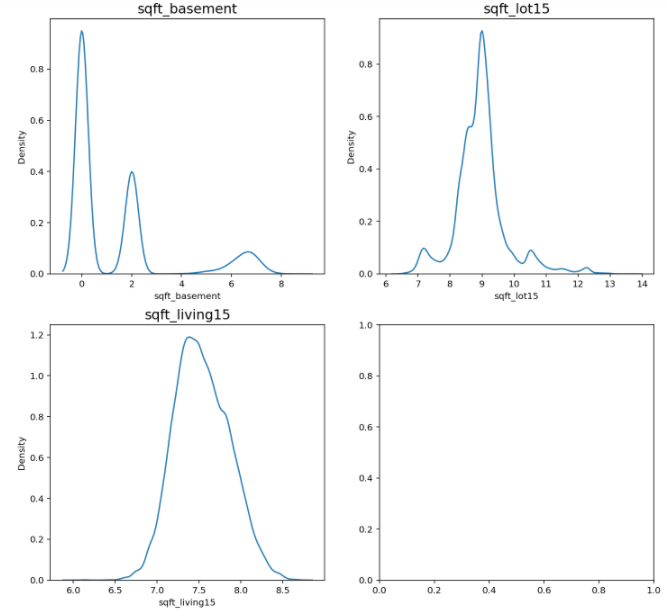
이전보다 치우침이 줄어든 분포를 확인할 수있습니다.
로그 변환시 치우침이 줄어드는 이유는 다음과 같습니다.
- 0<x<1 범위에서 기울기는 매우 가파릅니다. 그래서 x의 범위는 0-1로 매우 작은 반면 y는 (−∞,0)로 매우 발산하는 형태입니다.
- 따라서, 0에 치우친 값들을 로그 변환하면 값이 넓은 범위로 펼칠 수 있는 특징을 갖게 됩니다.
- 반면 x값이 1을 넘어가면 y의 기울기는 급격히 작아집니다. 즉, 큰 x 값들에 대해 y값이 크게 차이나지 않게되며 넓은 범위의 x값은 작은 y값에 모이게 됩니다.
'나의 공부 > 인공지능' 카테고리의 다른 글
| [fd_18] 딥러닝 들여다보기 (0) | 2022.01.22 |
|---|---|
| [fd_16] 파이썬으로 이미지 다루기 (0) | 2022.01.20 |
| 강화학습 ) 1강. Introdution to Reinforcement Learning (0) | 2022.01.12 |
| 데이터 전처리) 이상치란? Outlier? (0) | 2022.01.03 |
| 데이터 전처리) 결측치 처리 방법 (0) | 2022.01.03 |

